Table of Contents
1. Python Polars 도입 배경 : Pandas의 배신
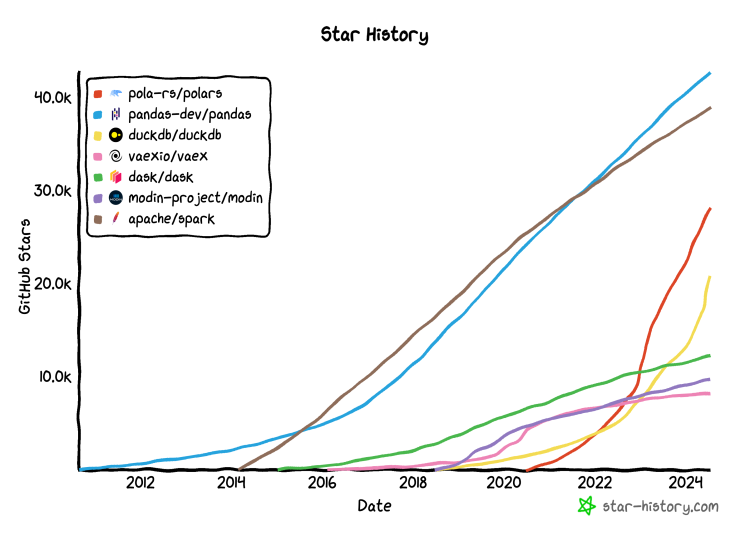
데이터 분석과 엔지니어링 ETL(Extract – Transform – Load) 작업에서 가장 많이 사용하는 라이브러리는 Python의 Pandas 일 것이다. 하지만, 대량의 데이터를 처리할 때, 혹은 다수의 배치를 처리하면서 메모리가 부족해질 때, pandas의 성능 문제가 발목을 잡는다. 실행 속도가 느려지고, 메모리 사용량이 증가하는 문제 때문에, 제 시간에 끝나야 할 배치가 약속대로 끝나지 못하는 상황이 발생한다.
내가 일하는 조직에서도 이러한 문제점을 확인했는데, 우리의 경우는 1개 배치가 대략 3시간에서 최대 6시간까지도 소요되는 이슈가 있었다. 어제만 그랬겠지, 3일만 그랬겠지, … 하다가 일주일 동안 이런 이슈가 발생했을 때는 분명 문제가 있다는 것이다. 최근 신규 고객사가 늘어나면서, 데이터 건수 자체가 대략 2배 이상 증가했는데, 이러한 영향이 이후 단의 배치 하나 하나에 이렇게까지 영향을 미칠 지는 그 누구도 예측하지 못했다.
이러한 상황을 극복하기 위해, 우리는 Pandas를 과감히 Polars로 대체하기로 의사결정했다. 이 글에서는 Pandas 기반 ETL의 문제점을 분석하고, 이를 해결하기 위한 대안으로 Python Polars를 소개하고, 어떤 상황에서 대체 방안을 고민해야 하는지를 풀어보고자 한다.
2. Python Polars의 차별점
Pandas의 성능 한계
Python Pandas는 강력하고 유연한 데이터 처리 기능을 제공하지만, 대량 데이터 환경에서는 몇 가지 성능 한계를 보인다.
- 단일 스레드 처리: pandas는 기본적으로 단일 코어를 사용하기 때문에 멀티코어를 활용한 병렬 처리가 어렵다.
- 다시 말해, 대량의 데이터를 처리할 때 pandas는 한 번에 하나의 작업만 수행하므로, 멀티코어 CPU를 최대한 활용하지 못하고 성능 병목이 발생할 수 있다.
- GIL(Global Interpreter Lock): Python의 GIL로 인해 pandas는 멀티스레딩을 활용한 성능 최적화가 제한된다.
- GIL은 Python 인터프리터가 한 번에 하나의 스레드만 실행하도록 제한하는 메커니즘으로, pandas가 멀티스레딩을 사용할 수는 있지만 실제로는 하나의 스레드만 실행되므로 성능 향상이 어렵다.
- 높은 메모리 사용량: pandas는 데이터를 한 번에 메모리에 로드한 후 처리하는 방식이므로, 데이터 크기가 증가할수록 메모리 부족 문제가 발생할 수 있다.
- 특히, 수십 GB 이상의 데이터를 pandas로 처리할 경우, 시스템의 메모리를 초과하여 프로세스가 비효율적으로 동작하거나 충돌할 위험이 있다.
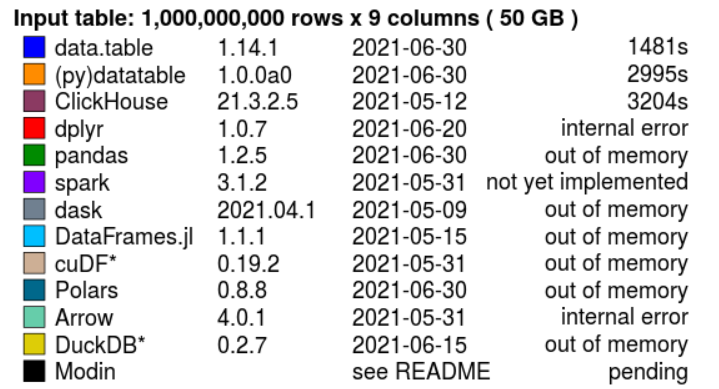
Python Polars란?
Polars는 고성능 데이터프레임(Dataframe) 라이브러리로, 대규모 데이터 처리에 최적화된 설계를 갖추고 있다. Apache Arrow 기반의 컬럼 저장 방식과 Lazy Evaluation(지연 실행) 기능을 활용하여 pandas보다 훨씬 빠르고 효율적인 데이터 처리 성능을 제공한다.
Polars는 Rust 언어로 설계되었으며, 이는 성능 최적화에 초점이 맞춰져 있다고 볼 수 있겠다. Rust는 메모리 안전성과 고속 실행 성능을 보장하는 언어로, C/C++과 유사한 저수준 성능을 제공하면서도 안전한 동시 실행을 지원한다. 이러한 Rust의 특성 덕분에 Polars는 다음과 같은 장점을 가진다:
- Zero-Cost Abstraction: Rust의 설계 원칙 덕분에 실행 시간 오버헤드 없이 고수준 API를 사용할 수 있다.
- 컴파일 타임에 최적화된 코드를 생성하여 런타임 성능 저하 없이 편리한 API를 제공할 수 있도록 함.
- 메모리 안전성: Rust의 엄격한 메모리 관리 기능을 통해 불필요한 메모리 누수를 방지할 수 있다.
- Rust는 빌림(Borrowing)과 소유권(Ownership) 개념을 도입하여 명시적인 가비지 컬렉션 없이도 안전한 메모리 관리가 가능함
- 멀티스레드 성능 극대화: Rust는 안전한 병렬 처리를 지원하여 Polars의 멀티코어 활용을 최적화한다.
- Rust의 Fearless Concurrency(두려움 없는 동시성) 특성 덕분에, 경쟁 상태(Race Condition) 없이 여러 스레드에서 안전하게 데이터를 처리할 수 있다.
ETL 측면에서 더 자세하게 보자면, Python Polars는 데이터 분석 및 ETL 파이프라인에서 성능을 극대화하기 위해 만들어졌고, pandas의 성능 병목을 해결하기 위한 다양한 기능을 포함하고 있다.
- Python뿐만 아니라 Rust에서도 사용 가능: 성능 최적화가 필요한 경우 Rust 언어에서 직접 사용할 수 있도록 설계되어 있다.
- 빠른 데이터 로딩과 변환: Polars는 Apache Arrow의 컬럼 기반 메모리 구조를 사용하여 대용량 데이터를 효율적으로 로드하고 변환할 수 있다.
- 병렬 처리 최적화: Polars는 기본적으로 멀티코어와 멀티스레드 처리를 지원하여 데이터 연산 속도를 극대화한다.
- Lazy Evaluation(지연 실행): 필요할 때만 연산을 수행하여 불필요한 메모리 사용을 방지하고 성능을 극대화한다.
- SQL과 유사한 쿼리 인터페이스 지원: Polars는 SQL 스타일의 데이터 조작 기능을 제공하여 기존 SQL 사용자들도 쉽게 활용할 수 있다.
import polars as pl
# 데이터프레임 생성
df = pl.DataFrame({
"id": [1, 2, 3, 4, 5],
"category": ["A", "B", "A", "B", "A"],
"value": [10, 20, 15, 25, 30]
})
# SQL 스타일의 그룹핑, 필터링, 정렬 적용
df_processed = (
df.groupby("category") # GROUP BY
.agg([
pl.col("value").sum().alias("total_value"),
pl.col("value").mean().alias("avg_value")
]) # ALIAS
.filter(pl.col("total_value") > 30) # WHERE
.sort("avg_value", descending=True) # ORDER BY
)
print(df_processed)3. Python Polars 설치 및 기본 사용법
Python Polars 설치 방법
Polars는 pip 명령어를 사용하여 쉽게 설치할 수 있다.
pip install polars기본 데이터 로딩 및 처리 예제
Polars의 데이터프레임을 생성하고 간단한 데이터 처리 작업을 수행하는 예제는 아래와 같다. df 생성 과정은 Pandas와 거의 유사하다.
import polars as pl
# 데이터프레임 생성
df = pl.DataFrame({
"name": ["Alice", "Bob", "Charlie"],
"age": [25, 30, 35],
"salary": [50000, 60000, 70000]
})
# 필터링 예제
filtered_df = df.filter(pl.col("age") > 28)
print(filtered_df)
4. Pandas Polars 대체를 고민한다면…
Polars 도입 체크리스트
아래와 유사한 상황이라면, 지금 쓰고 있는 Pandas 기반 모듈 대신 Python Polars를 고려하는 것이 좋다.
- ✅ 대용량 데이터 처리가 필요할 때 (수백 MB~GB 이상의 데이터)
- 예: 실시간 로그 데이터 분석, 머신러닝 학습 데이터 전처리
- ✅ ETL 배치 작업 시간이 너무 오래 걸릴 때 (3시간 이상)
- 예: 하루 단위 배치 작업이 비효율적으로 길어지는 경우
- ✅ 메모리 사용량 최적화가 필요한 경우
- 예: pandas로 처리할 때 메모리 부족 에러가 발생하는 경우
- ✅ 병렬 처리 및 멀티코어 활용이 필요한 경우
- 예: 단일 스레드 실행이 비효율적인 대규모 데이터 처리 환경
- ✅ Lazy Evaluation을 통한 성능 최적화가 필요할 때
- 예: 쿼리를 한꺼번에 실행해 연산 비용을 줄여야 하는 경우
- ✅ Apache Arrow 기반의 고성능 데이터 처리가 필요할 때
- 예: 다양한 데이터 소스에서 가져온 데이터를 빠르게 변환하는 경우
- ✅ pandas에서 GIL로 인해 성능이 제한될 때
- 예: 멀티스레딩을 활용하고 싶지만 pandas가 지원하지 않는 경우
5. 다음 편 예고: Python Polars vs Pandas 비교
다음 글에서는 Python Polars와 pandas의 성능을 실제로 비교하는 실험을 진행해보고자 한다. 동일한 데이터셋을 사용하여 두 라이브러리의 속도를 테스트하고, 어떤 차이가 있는지 확인해보고 어떤 연산 등에서 Polars가 필요한 상황인지 직접 분별하는 것이 좋겠다.
다음 글에서 다룰 내용:
- Python Polars vs Pandas의 속도 비교 테스트
- 두 연산 간 메모리 사용량 비교
- ETL 작업에서 두 라이브러리의 효율성 차이 분석
Python Polars를 활용한 성능 최적화 전략과 수행 과정을 확인해보고 싶다면, 다음 글도 기대해주시라~! 🚀